

Velké srovnání MySQL (MariaDB) a PostgreSQL
Databáze jsou nedílnou součástí jakékoliv IT infrastruktury a bez nich bychom si nic “nepamatovali”. Jak čas plyne, tak rostou i nároky na databázové systémy, jejich funkcionalitu a rychlost. Zároveň roste počet specializovaných a nerelačních databází. Většina z nich je ale zpoplatněna.
V dnešním článku budeme rozebírat dvě databáze, které jsou u komunity velice oblíbené, jsou open-source a vývoj jde stále vpřed.
Krásným příkladem je právě MySQL, která za posledních pár aktualizací udělala neuvěřitelný skok vpřed a “dotáhla” se už na PostgreSQL, co se funkcionality týče.
Každá databáze se hodí na jiné projekty a přesně to je obsahem našeho článku.

VPS Centrum
Vyzkoušejte zdarma naši aplikaci pro správu serveru a domén. Budete si připadat jako zkušený administrátor.
Nadále jsou pro vás připraveny články o databázích u nás v nápovědě.
Základní informace
Rozebereme základy jednotlivých řešení a pár zajímavostí ke každé databázi. Podíváme se na rozdíly v indexech, jak se liší kódování a pronikneme spolu do jejich správy.
Nemůžeme ani opomenout, jak si DB stojí v oblasti replikací a clusteringu.
MySQL (MariaDB)
Jedná se o nejpopulárnější databázi, kterou využívá 39% vývojářů. (v roce 2019). Je to nejvíce používána databáze na většině aplikací a stránek. MySQL také využívá většina CMS jako např. WordPress, Joomla nebo Drupal a díky tzv. LAMP (Linux, Apache, MySQL a PHP) stacku, jako open-source kit pro webové aplikace narazíte na MySQL na každém druhém kroku. Díky tomu je MySQL jednodušší na implementaci oproti PostgreSQL. Hlavně ladění nezabere tolik času a dosáhnete skvělých výsledků za malé úsilí.
MySQL je relační databázový model (RDBMS) a používá tabulky, jako základní komponentu. Hlavně má skvělou paletu funkci jako PostgreSQL. Mnoho skvělých funkcí přibylo hlavně v posledních aktualizacích viz. screenshot pod námi.
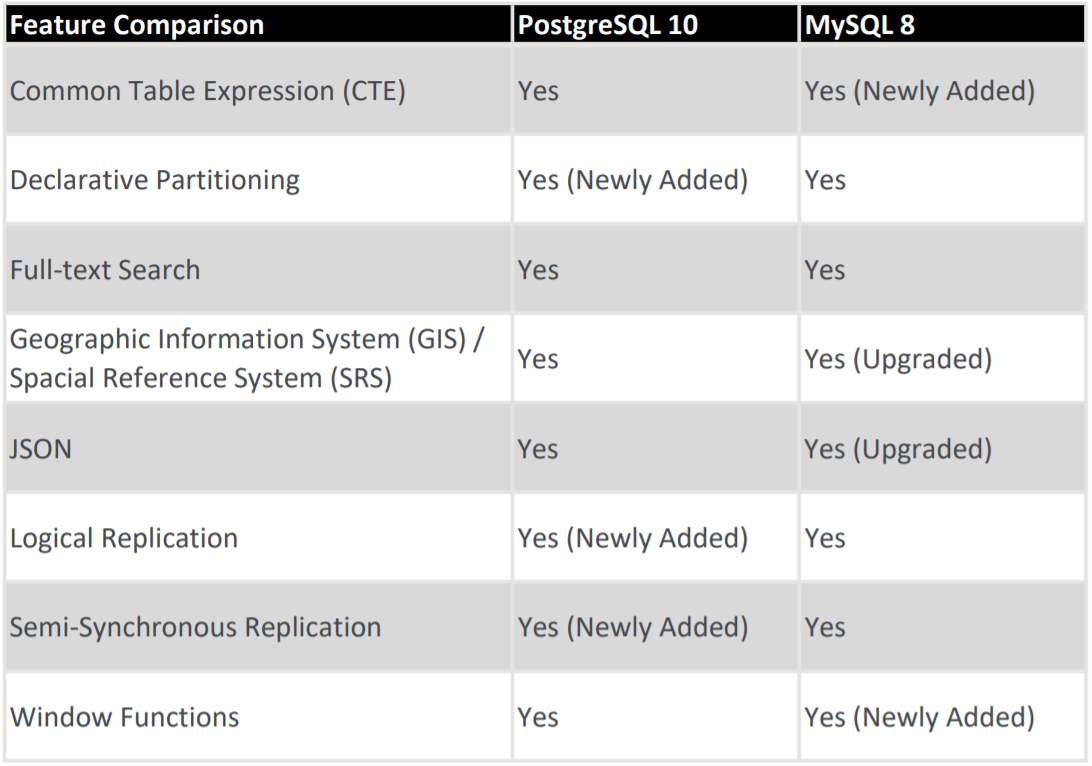
zdroj: xplenty.com
Před několika lety by byl vítězem v mnoha ohledech právě PostgreSQL, ale díky velké podpoře komunity a vývojářů se MySQL neustále vylepšuje. Dnes však jednoznačný vítěz neexistuje. Každá z databází má to své a opravdu záleží na konkrétních požadavcích vašeho projektu.
Nástroje pro správu MySQL jsou:
Pokud jste začátečník, tak nejvíce doporučujeme nástroj Adminer. Je to nejsnazší cesta, jak se správou MySQL začít a umí většinu věcí, které budete ze začátku potřebovat. Také Adminer najdete na většině hostingů včetně toho našeho a vyplatí se v něm orientovat.
Naše další doporučení dostane nástroj SQLyog. V community verzi je zdarma a spousta programátorů si jej vychvaluje, protože je jednoduchý a umí spousty zajímavých funkcí. Např. kopírovat data mezi databázemi. To Adminer neumí.

Freelo - Nástroj na řízení úkolů a projektů
Přidej se, pozvi svůj tým a klienty, rozděl práci a sleduj, jak se úkoly dají do pohybu.
PostgreSQL
Je objektově-relační databázový systém (ORDBMS) s důrazem na rozšiřitelnost a dodržování standardů. Hlavní rozdíl je v tom, že neukládá pouze informace o tabulkách a sloupcích, ale umožňuje definovat i datové typy, typy indexů a funkční jazyky.
Druhá nejpopulárnější databáze z hlediska počtu instalací. Jedná se také o open-source projekt a na jeho vývoji se podílí vývojářská komunita z celého světa včetně menších a velkých firem. Můžete si databázi také přizpůsobit pomoci vlastních pluginů. Pomocí pluginů můžete pro PostgreSQL začlenit funkce vytvořené pomoci jiných programovacích jazyků, jako jsou C / C ++, Java a další.
PostgreSQL je přizpůsobená pro spravování velkého počtu databází. Nemáte omezení na velikosti svých databází. Chris Travers – Databázový administrátor z Adjust.com se svěřil, že „jeho firma používá PostgreSQL k správě skoro 4 PB dat“. To je 4.000 TB. Zároveň uvádí, že „databáze zpracovávají zvenčí od 100 do 250 tisíc požadavků za sekundu“.
PostgreSQL je skvělý pro složité dotazy. Pokud potřebujete provádět komplikované operace čtení a zápis, při použití dat, která vyžadují ověření, je PostgreSQL vynikající volbou. ORDBMS však může zaznamenat zpomalení při práci s operacemi jen pro čtení. (Tady vyniká naopak MySQL)
Multi-version-concurrency control (MVCC) je jedním z nejdůležitějších důvodů, proč si podniky vybírají PostgreSQL. MVCC umožňuje totiž různým readers / writers interagovat a spravovat PSQL databázi současně. To eliminuje potřebu funkce tzv. read-write lock pokaždé, když někdo potřebuje interagovat s daty, čímž se zvyšuje účinnost. MVCC toho dosahuje prostřednictvím „snapshot isolation“ (jak to nazývá Oracle). Snímky představují stav dat v určitém okamžiku. Dá se to přirovnat ke snapshotum VPSek.
Díky Postgre můžete využít funkci, která vrátí řádek s výstupem hodnot. S nimi můžete v dotazech pracovat jako s tabulkou. Dále můžete definovat vlastní agregační a window funkce.
Nástroje pro správu PostgreSQL (celkem 76 nástrojů):
- Adminer
- PgAdmin
- PhpPgAdmin
- Db forge studio for PostgreSQL
- Datagrip
Správa PostgreSQL databází je oproti MySQL složitější. Většina nástrojů nejsou přívětivá a jsou mnohem složitější. Je to díky větším počtu funkcí, a že s designem nástrojů už si nikdo takovou práci nedal. PgAdmin nebo PhpPgAdmin jsou zastaralé a orientace je v nich náročnější, ale je to hlavně o zvyku. Pokud už umíte s Adminerem, tak to budete mít mnohem jednodušší, protože umí spravovat obě databáze. Naše doporučení pro začínající programátory tedy bude stále zůstávat právě u Admineru.
Jak to je s indexy?
Indexy pomáhají zlepšovat výkon databáze, protože povolí databázovému serveru najít a načíst specifický řádek mnohem rychleji než bez indexu. Bohužel to má i druhou stranu mince. Čím více indexu v databázovém systému máte, tím je provoz databáze náročnější na systémové prostředky serveru.
Pokud databáze nemá index, tak musí začít od prvního řádku a projít kompletně celou tabulku, aby našla hledané řádky. Samozřejmě čím větší tabulka, tím náročnější výpočetní operace.
MySQL Indexy
- Indexy lze uložit jako tzv. B-tree, jako je INDEX, FULLTEXT, PRIMARY KEY and UNIQUE.
- Indexy uložené na R-trees, jako jsou indexy nalezené na typech prostorových dat.
- Při použití indexu FULLTEXT hašuje indexy a obrácené seznamy.
PostgreSQL Indexy
- Podporuje hašovací indexy a B-tree indexy.
- Částečné indexy, které organizují informace pouze z části tabulky.
- Můžete vytvořit index, jako výsledek výrazu nebo funkce namísto jednoduché hodnoty sloupce.
Kde a jak jsou databáze nasazené?
Typicky jsou instalace prováděné hlavně na různých variacích linuxových serverů a cloudů. Obě databáze jsou dostupné na různé operační systémy. Samozřejmě nejvíce databází najdete na unixových serverech.
PostgreSQL
Je naprogramovaná v jazyce C a podporuje tyto programovací jazyky:
C++, Delphi, Perl, Java, Lua, .NET, Node.js, Python, PHP, Lisp, Go, R,D,Erland.
Máte k dispozici také REST API pro jakoukoliv PG databázi.
MySQL
Je vytvořen v jazyce C a C++ a stejné programovací jazyky jako PostgreSQL. Jen pro Javu je potřeba použít MySQL Connector/J. Implementace databáze může běžet také na cloud-based platformách.
Jaké typy replikací/clusteringu jsou dostupné?
Replikace je proces, při kterém můžete automaticky kopírovat data z master do slave databáze. To přináší samozřejmě několik výhod:
- Jednoduché a spolehlivé zálohy
- Rozložení zátěže pro zlepšení výkonu
- Tým analytiků může pracovat na ´slave´ databázi, kde nebude zpomalovat výkon hlavní databáze master
Clustering
V kontextu databází clustering znamená použití sdíleného úložiště a poskytování více databází pro koncové uživatele. Front-end servery sdílejí IP adresu a síťový název clusteru, který používají klienti k připojení a sami databáze umí rozhodnout, jaká DB bude pro určitého návštěvníka zodpovědná za zpracování požadavků.
PostgreSQL
Používá synchroní replikaci nebo-li 2-safe replication, která využívá dvě instance databáze spuštěné současně. Kde je ´master´ databáze synchronizovaná se ´slavem´. Pokud obě databáze selžou současně, data se neztratí. Při synchronní replikaci čeká každý zápis na potvrzení od obou databází (master + slave).
MySQL
Replikace je jednosměrná (asynchronní), kde jeden server funguje jako hlavní (master) a další jako slaves. Můžete replikovat všechny databáze, vybrané databáze nebo dokonce pouze vybrané tabulky v databázích. MySQL cluster je technologie poskytující tzv. shared-nothing nebo-li bod bez jediného bodu selhání a vlastností auto-sharding (rozdělení) pro systém správy databází.
Interně cluster používá synchronní replikaci pomocí dvoufázového mechanismu potvrzení. Tak je zaručeno, že data jsou zapsaná do více uzlů. To je v rozporu s tím, co se obvykle označuje jako „replikace MySQL“ což je asynchronní.
Proč vývojáři vybírají jednotlivá řešení?
PostgreSQL
je objektově-relační programovací jazyk (ORDBMS), takže slouží jako můstek mezi objektově orientovaným programováním a relačním / procedurálním programováním (stejně jako C ++). To vám umožní definovat dědičnost objektů a tabulek, což se promítá do složitějších datových struktur.
ORDBMS je geniální, pokud pracujete s daty, které nespadají do přísně relačního modelu.
Hodí se do velkých systémů, kde je třeba data autentizovat a rychlost read / write je kritická pro úspěch. PostgreSQL podporuje také řadu vylepšovačů výkonu, které jsou k dispozici v proprietárních řešení. Např. read locks, SQL server a podpora geoprostorových dat.
Obecně platí, že PostgreSQL je nejvhodnější pro systémy, které vyžadují provádění složitých dotazů nebo skladování a analýzu dat. PostgreSQL oproti MySQL je složitější na správu a člověk zde potřebuje více technického know-how.
MySQL
MySQL se zaměřuje hlavně na rychlost a spolehlivost. Bez zahrnutí určitých funkcí SQL zůstane databáze lehká. Největší výkon z MySQL dostaneme při souběžné funkci jen pro čtení. To z DB dělá perfektního kandidáta pro specifické účely business intelligence.
Je první volbou pro webové projekty, které vyžadují databázi pouze pro datové transakce a nic složitého. MySQL má dobré ohlasy v systémech online analytického zpracování tzv. OLAP, kde je důležitá pouze vysoká rychlosti čtení. Databáze se však může potýkat s nedostatečným výkonem, jakmile se zvýší zatížení nebo bude zpracovávat komplexní dotazy a server je nebude stíhat zpracovávat. V případě clusteru se dá zátěž jednoduše rozložit a komplexní dotazy mohou běžet na ´slave´ databázi.
Je otázkou, zda se vám vyplatí si budovat složitější infrastrukturu. Můžete vybírat i ze široké škály paměťových modulů. To vám dává flexibilitu při integraci dat z různých typů tabulek. MySQL 8.0 podporuje tyto storage enginy:
InnoDB
Jeden z formátů uložiště dat v databázi MySQL. Storage engine je softwarová komponenta, kterou DBMS používá ke CRUD (Create, Read, Update, Delete) operacím nad databází. Řídící systém (DBMS) má obvykle API, díky kterému může uživatel přímo ovládat engine, aniž by použil uživatelské rozhraní nadřazeného DBMS.
MyISAM
Další ze storage enginu a až do verze 5.1 byl výchozím formátem úložiště dat v MySQL. Ukládá každou tabulku ve dvou souborech:
- .MYD – datový soubor
- .MYI – indexový soubor
Tabulky MyISAM mohou obsahovat buď dynamické řádky, nebo statické řádky (pevné délky). MySQL se rozhodne o tom, který formát použije na základě definice tabulky.
Protože MyISAM je jeden z nejstarších úložných enginů, které byly zařazeny do MySQL, obsahuje velké množství funkcí, které byly vyvinuty během let jeho existence, aby uspokojily potřeby požadované jeho uživateli.
- Uzamykání a souběžnost
- Automatická oprava
- Ruční oprava
- Indexové funkce
- Pozdržené zápisy klíčů
Memory nebo HEAP
Vysoce výkonné úložiště, které data uchovává pouze v operační paměti, při restartu serveru jsou data ztracena. Nasazení MEMORY storage enginu se hodí pro důležitá, vysoce dostupná a často aktualizovaná data.
Pár zajímavostí:
- Místo pro tabulky MEMORY je přiděleno v malých blocích
- Tabulky používají pro input 100% dynamické hašování
- Memory zahrnuje podporu sloupců AUTO_INCREMENT
- Tabulky nemohou obsahovat sloupce BLOB nebo TEXT
- Non-temporary tabulky jsou sdílené mezi všemi klienty
CSV
Jak název vypovídá, tak tento storage engine ukládá data v textovém formátu CSV. Tabulky CSV jsou ekvivalentem externích tabulek Oracle. Mohou být použity k importu dat z vašeho oblíbeného softwaru tabulkových procesorů, k výměně dat z nebo s jinými zdroji dat. CSV může sloužit i k migraci dat z jiného databázového systému do MySQL.
Tabulky CSV nelze indexovat a nepodporují transakce.
Archive
Stroj uzpůsobený pro ukládání velkého množství neindexovaných dat. Tento paměťový modul je optimalizován pro vysokorychlostní vkládání. Komprimuje data, tak jak jsou vložená. Při načítání jsou řádky nekomprimovaný na vyžádání a řádky nemají žádnou cache. Archive také nepodporuje transakce.
NDB/NDBCLUSTER
Další známy storage engine. Umožňuje clusterovým tabulkám seskupování. To znamená, že máte více master databází, do které mohou ostatní vkládat svá data, aktualizovat a mazat ve stejne tabulce. NDB má zamykání na úrovni řádku, ale ne pro MVCC. Vzhledem k určitým architektonickým omezením způsobu, jakým se server MySQL provádí připojování, fungují s NDB spíše špatně. Z toho důvodu se pro vyhledávání nejlépe používají primární klíče z jedné tabulky. Takže byste pravděpodobně nepřenášeli celou svou webovou databázi například do clusteru NDB.
Merge
Sloučení dat z několika MyISAM tabulek o stejné struktuře. Nejedná se o samotné ukládání dat, ale o poskytnutí kontejneru. Tento engine úzce souvisí s tím, jak jsou oddíly zpracovávány a vytvářeny.
Sloučené tabulky vám pomohou snadněji spravovat velké objemy dat. Mohou být užitečné pro přihlášení do aplikací, protože můžete snadno odstranit stará data vynecháním podkladových tabulek. Můžete si je představit jako UNION ALL Views. Jedna věc, kterou je třeba mít na paměti u tabulek MERGE, je příkaz CREATE, který nekontroluje kompatibilitu podkladových tabulek. Tím pádem se nezjistí, jestli je tabulka kompatibilní, dokud se nezkusí.
Federated
Storage engine federated umožňuje přístup k datům ze vzdálené databáze MySQL bez použití technologie replikace nebo clusteru. Dotaz na místní tabulku federated automaticky vytáhne data ze vzdálených (federated) tabulek. V místních tabulkách nejsou uložená žádná data.
Jak se liší kódování?
Zde jsou tři oblasti rozdílů mezi kódováním pomocí MySQL vs. PostgreSQL, o kterých byste měli vědět:
- Citlivost na malá a velká písmena
- Výchozí znakové sady a řetězce
- Příkazy IF a IFNULL vs. CASE
Rozlišování malých a velkých písmen
MySQL nerozlišuje velká a malá písmena. Při psaní dotazů nemusíte používat velká písmena, protože se objevují v databázi. PostgreSQL rozlišuje velká a malá písmena. Řetězce je nutné psát přesně tak, jak jsou uvedeny v databázi, jinak se dotaz nezdaří.
Výchozí sady znaků a řetězce
U některých verzí MySQL je nutné převést znakové sady a řetězce na UTF-8. U PostgreSQL to nutné není. Syntaxe UTF-8 navíc není v PostgreSQL povolena.
Příkazy IF a IFNULL vs. CASE
V MySQL je naprosto v pořádku používat příkazy IF a IFNULL. V příkazech PostgreSQL příkazy IF a IFNULL nefungují. Místo toho musíte použít příkaz CASE.
MySQL – IF
Syntaxe
“IF(condition, value_if_true, value_if_false)”
Příklad – Vrátí 5, když podmínka je TRUE nebo 10 když je FALSE:
“SELECT IF(500<1000, 5, 10);”
MySQL – IFNULL
Syntaxe
“IFNULL(expression, alt_value)”
Příklad – Vrátí zadanou hodnotu, pokud je výraz NULL, jinak vrátí výraz
“SELECT IFNULL(„Hello“, „Vas-Hosting.cz“);”
PostgreSQL – CASE
“
CASE
WHEN condition_1 THEN result_1
WHEN condition_2 THEN result_2
[WHEN …]
[ELSE result_n]
END
“
Podpora JSON
JavaScript Object Notation – neboli JavaScriptový objektový zápis je způsob zápisu dat (datový formát), který není na žádné počítačové platformě a je určený pro přenos dat, která mohou být organizovaná v polích nebo agregována v objektech.
Vstupem může být libovolná datová struktura např.
- číslo
- řetězec
- boolean
- objekt nebo z nich složené pole
A my se teď podíváme, jak to je s podporou JSON v databázích, které v tomhle článku rozebíráme.
MySQL a JSON
Chvíli to trvalo, než vývojáři mohli uložit JSON do bloků v MySQL a buď sním manipulovali v aplikaci nebo použili komplikované funkce nebo manipulovat s uloženými procedurami. MySQL a zejména InnoDB nejsou zrovna nejlepší při ukládání a manipulaci s blobovými daty. Může být uložen neefektivně se spoustou režijních nákladů. To vše se změnilo s příchodem aktualizace MySQL 5.7 a najednou byl JSON nativně podporovaný datový typ.
Hlavně verze 5.7 zavedla sadu funkcí JSONu pro přímou manipulaci se sloupci, ale dalo by se říct, že JSON se dal používat pořádně až po aktualizaci MySQL 8.0, kde přibyly další funkce jako:
- JSON_ARRAYAGG ()
- JSON_OBJECTAGG ()
- operátor JSON – >>
MySQL dokumentace k verzi 8.0 popisuje nového operátora jako “podobné operátoru – >”, ale to provádí také dekódování hodnoty JSON. Ve starších verzích MySQL byla sada funkcí UDF již nějakou dobu k dispozici, aby mohla komunita do svých databází instalovat a manipulovat s JSON.
Podrobný návod, jak pracovat s JSON a MySQL.
PostgreSQL a JSON
Mnohem delší historii má JSON právě v PostgreSQL od verze 9.2. V této verzi byl JSON už nativně podporovaným datovým typem a pro dotazování a manipulaci s ním bylo k dispozici již několik funkcí.Ve verzi 9.3 byla podpora značně rozšířena. Kromě funkcí existovalo i několik desítek operátorů, které jsou stále k dispozici i v nejnovější verzi PostgreSQL, 9.6.
Ve verzi 9.4 byl datový typ JSON doplněn datovým typem JSONB, který je stále podporován i v 9.6. Existuje také několik desítek funkcí JSONB, jedna pro každou odpovídající funkci JSON a PostgreSQL 9.6 přidal ještě navíc JSONB_Insert ().
Možná jednou z největších výhod JSONB oproti prostému textu JSON je to, že podporuje indexování. Můžete samozřejmě vytvořit funkční indexy v Postgresu, takže můžete indexovat prostý text, ale stále je lepší a efektivnější indexovat JSONB než JSON.
Níže si ukážeme validní výrazy json nebo jsonb:
- Jednoduchá skalární / primitivní hodnota
- Primitivní hodnoty mohou být čísla, citované řetězce, true, false nebo null SELECT ‚5‘::json;
- Řada nul nebo více prvků (prvky nemusí být stejného typu) SELECT ‚[1, 2, „foo“, null]‘::json;
- Objekt obsahující páry klíčů a hodnot
- Všimněte si, že klíče objektů musí být vždy uvedeny jako řetězce SELECT ‚{„bar“: „baz“, „balance“: 7.77, „active“: false}‘::json;
- Pole a objekty mohou být uloženy libovolně SELECT ‚{„foo“: [true, „bar“], „tags“: {„a“: 1, „b“: null}}‘::json;
Podrobný návod jak pracovat s JSON a PostgreSQL.
Finální shrnutí
MySQL bude ideální pro váš projekt, pokud budete potřebovat vysoce zabezpečený RDBMS pro webové aplikace nebo vlastní řešení, ale ne pokud potřebujete plně kompatibilní RDBMS s SQL schopný rychle provádět složité úkoly. Mezitím bude PostgreSQL ideální pro váš projekt, pokud se vaše požadavky budou točit kolem složitých postupů, integrace, složitých návrhů a integrity dat, a ne kolem vysokorychlostního a snadného nastavení.
Před několika lety by byl vítězem v mnoha ohledech právě PostgreSQL, ale díky velké podpoře komunity a vývojářů se MySQL neustále vylepšuje a můžeme říci, že nyní nelze označit jasného vítěze a opravdu záleží na konkrétních požadavcích vašeho projektu.
Stále platí, že MySQL je lepší pro webové stránky a online transakce a PostgreSQL pro velké a náročné analytické procesy, ale každým rokem se obě databáze k sobě přibližují a za rok může být zase všechno úplně jinak.

Začněte s databázemi a objednejte si server ještě dnes
Zdroje:
https://www.xplenty.com/blog/postgresql-vs-mysql-which-one-is-better-for-your-use-case/
https://hackr.io/blog/postgresql-vs-mysql

